Large Language Model (LLM)
Icon

Function
The LLM component allows your model to interact with external Large Language Models (LLMs).
Key Points
- Model Selection: Specify and configure various large language models.
- Dynamic Data Input: Use input ports to dynamically feed the LLM with real-time data from your simulation model.
- Formatted Output: Define the data format for the LLM's response, making it ready for immediate use in subsequent modeling steps.
- Prompt Engineering: Flexibly edit both system and user prompts.
- Entity Population Support: Apply the LLM component to an entire population of entities, enabling each agent to interact with the LLM independently.
- External Tools (Coming Soon)
-
API Key Configuration
To access LLM services, you must first correctly configure your API Key in Personal Center --> Settings --> Credentials.
The API Key is stored locally only and is never uploaded to our servers. Consequently, you will need to re-enter it on each new device, even when using the same account.
For details on API configuration for different models, please refer to the official documentation from the third-party providers. For example:
- Google Gemini:
https://ai.google.dev/gemini-api/docs/api-key - OpenAI:
https://platform.openai.com/docs/api-reference/introduction
- Google Gemini:
-
Cost and Efficiency
Carefully consider the cost and efficiency of LLM interactions. API calls can be resource-intensive, especially when dealing with large entity populations, so configure them prudently.
How It Works
To use the LLM component, you simply drag it into any process on your canvas. This allows you to integrate the power of Large Language Models directly into your model's logic flow.
Core Execution Cycle
The component's execution follows this sequence:
- Trigger: Execution begins upon receiving a Trigger signal.
- Request: The system sends a composite prompt, combining the System Prompt and the User Prompt, to the Large Language Model (LLM).
- Response: The LLM processes the request and returns the result to the component's output port.
- Access: Subsequent steps in the process can access this result using the syntax
LLM_object_name.output_port_name.
Dynamic Data Injection
You can inject real-time simulation data into your prompts using placeholders.
- The system automatically substitutes placeholders in the User Prompt with the current data from the corresponding Input Port.
- Placeholder Syntax:
{input_port_name}
If the User Prompt is Current speed is {speed} km/h, the system will replace {speed} with the current value from the speed input port.
Asynchronous Execution
When used as a step for entity behavior, the LLM component executes in asynchronous mode to optimize performance.
-
Benefit: Parallel Processing & Increased Efficiency
Each entity's call to the LLM is an independent, parallel task. The system does not block while waiting for one request to complete, which significantly increases the overall simulation speed.
-
Note: Execution Timing Delay
Due to its asynchronous nature, the result of this behavior will be available later in the current tick (simulation step) compared to standard synchronous processes. This delay is a critical consideration when designing subsequent logic that directly depends on this component's output.
Configuration
The main configuration panel for the LLM component is divided into several sections.
Model
-
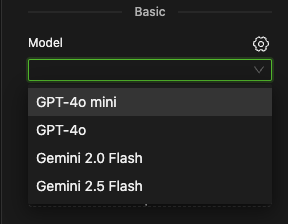
Select your desired large language model from the Model dropdown menu.
-
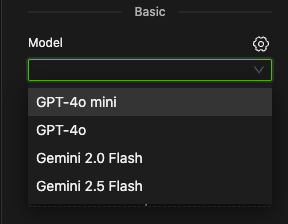
After selecting a model, click the settings icon ⚙️ on the right to adjust its specific parameters, such as Temperature.
-
Note: External tools are not yet supported.
Input Port
Input ports are used to provide the LLM with dynamic state information from your model.
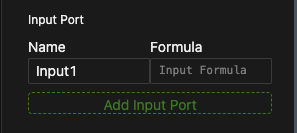
- Click Add Input Port to add a new input port.
- Name the port in the Name field.
- Enter an expression in the Formula field or link it to a model data object using a state chain.
Output Port
Output ports receive and store the LLM's response for use in subsequent modeling processes.
-
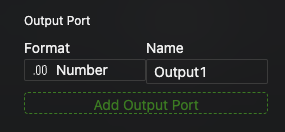
Click Add Output Port to add a new output port.
-
In the Format dropdown on the left, specify the data format for the response (e.g.,
Number,String,Boolean,List).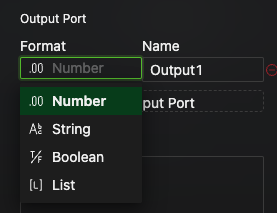
-
If you select
List, you must also specify a uniform data type for all its elements.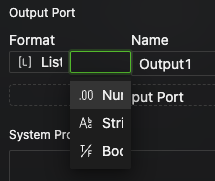
-
-
In the Name field, enter a name for your port.
System Prompt
This is where you define the overall context and systemic instructions for the conversation. Use it to specify the model's role, its mode of operation, and its behavioral boundaries. These instructions remain in effect throughout the interaction.
User Prompt
This is the core of the interaction, containing the specific instructions or questions you direct to the model.
A special syntax, {input_port_name}, is used to reference data from an input port. At runtime, the system will automatically substitute this placeholder with the latest data from the corresponding port.
- Debugging Strategy: First, ensure your model runs correctly, then focus on fine-tuning the LLM component's configuration. Start with smaller, more cost-effective models (like GPT-4o mini) to validate your logic before scaling up to more powerful ones.
- Token Consumption: Each use of the
{input_port_name}syntax in a prompt consumes tokens equivalent to the value of the data in that port. If you only need to mention the port's name rather than its value, use Markdown's code formatting (e.g.,port_name) to avoid unnecessary token consumption. - Handling Complex Data: When an input port's data is in a format that uses curly braces, such as a Dict, use double curly braces
{{key: value}}in the prompt for correct parsing. - Prompt Placement: While not mandatory, we recommend placing the
{input_port_name}syntax in the user prompt rather than the system prompt. This helps maintain a clear separation of roles. - Multiple Outputs: If you have configured multiple output ports, you will typically need to instruct the LLM clearly in your prompt on how to structure and direct its output to the different ports.
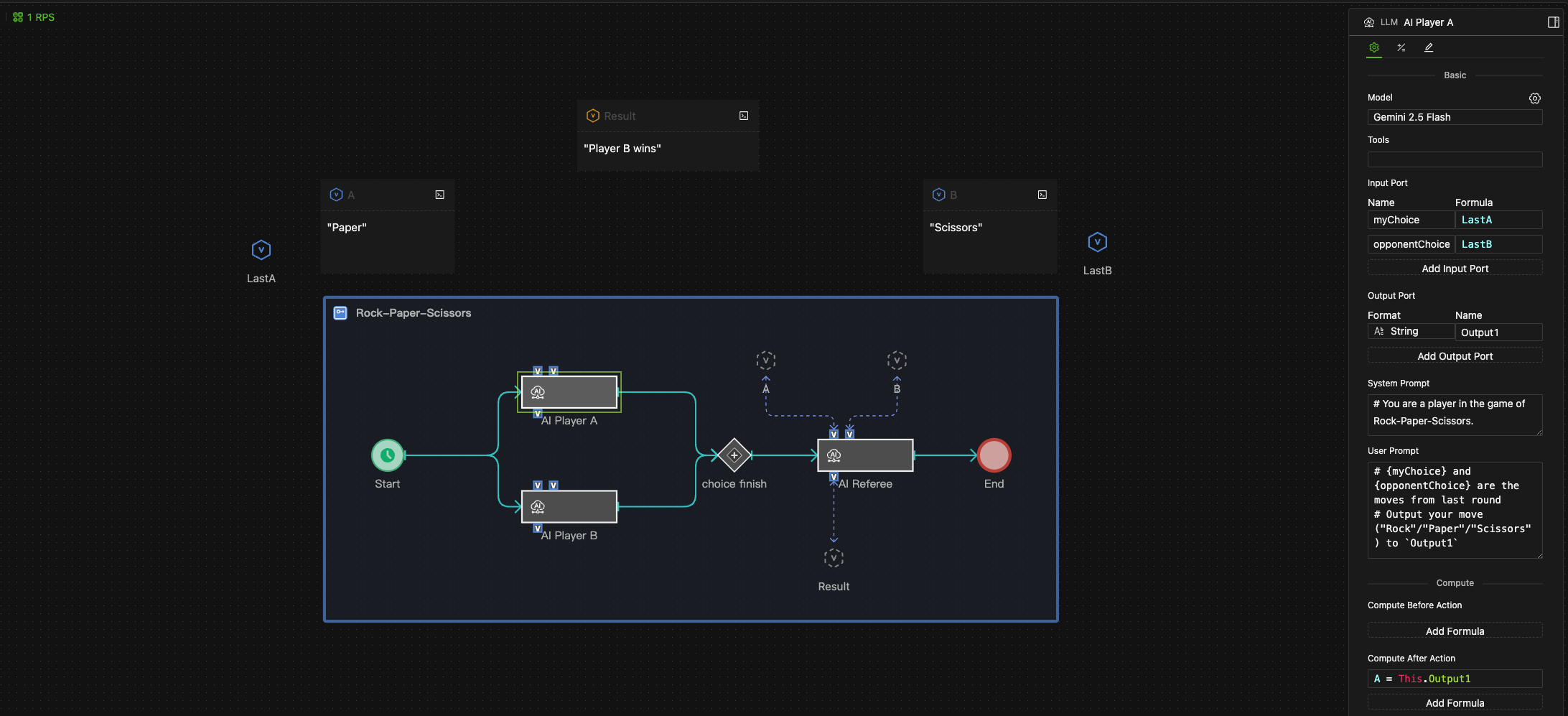
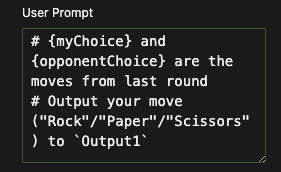
Example Use Case
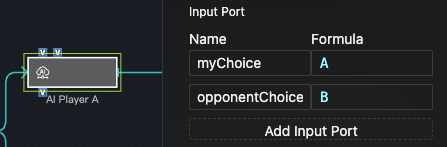
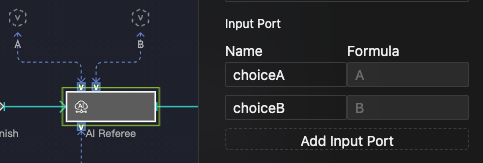
This example shows a Rock-Paper-Scissors game where two LLM objects act as players and a third acts as the referee.